実践力の養成1
回答
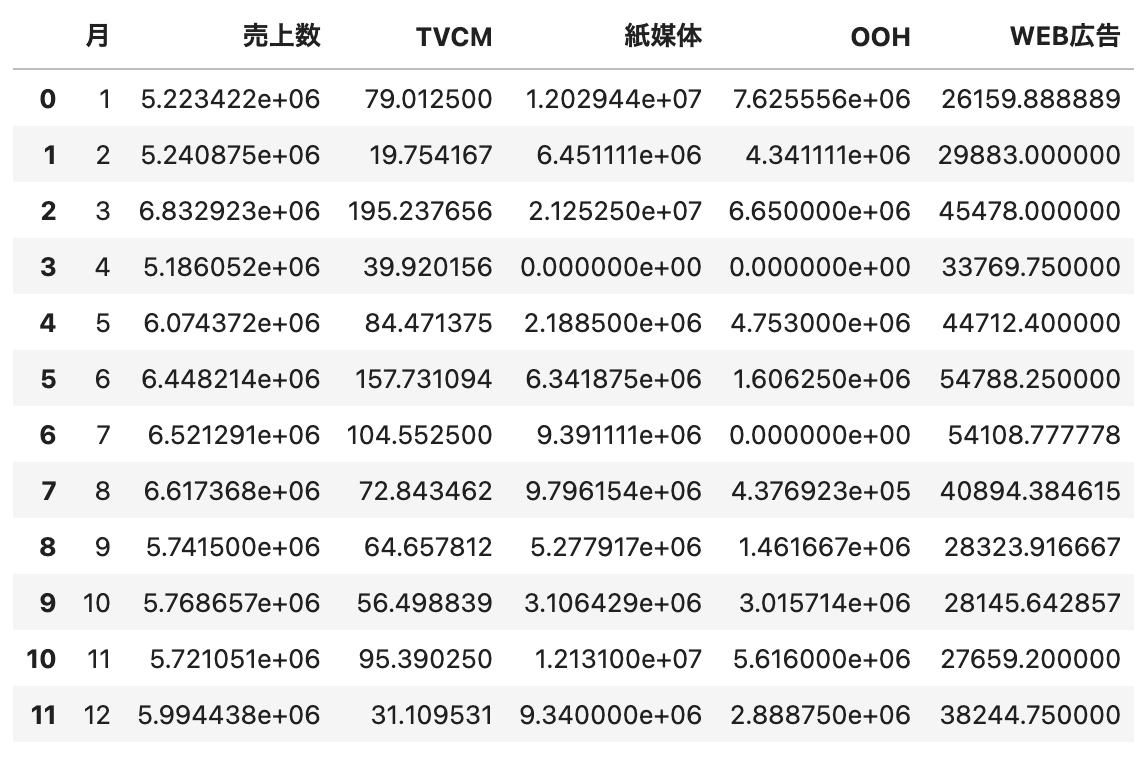
「効果があった」という主張は言及しやすい(もちろん、擬似相関には注意が必要です)のですが、「効果がなかった」という主張は非常に難しい側面があります。
特に、今回のモデルは良くても決定係数~0.7程度ですから、モデルの精度としてもまだ向上の余地があり、OOHの効果を十分に反映できていない可能性がある点は、分析者として気をつけるべきです。
モデルの結果から何かを主張するのであれば、そのモデルの「信頼性」(≒精度、妥当性)が担保されていることが前提です。
経営層が効果あると思って投下しているのであれば、OOHの効果が見えるようなチューニングが足りていない可能性があります。
例えば、
・OOHの効果が時間遅れで発生する可能性があれば、ラグを考慮して、OOHのデータを1週間や2週間ずつずらしたものを説明変数として加える
・残存効果や非線形効果のチューニングを行う(係数の調整、非線形の式の変更、など)
・特にOOHは屋外であることから、季節性の影響も大きそうなため、「月」との交互作用項を加える
などです。
これらを施しても効果が見えなかったり、あるいは、他のチューニングで決定係数が0.9近くまで上がっているのにOOHの効果が薄かったり、ということであれば、確かにOOHの広告費は抑えた方が良いという主張にも繋がり得ると思います。
また、回帰係数のp値も併せて見た方が良いかと思います。
あとは、MMMの構築目的にも依存すると思います。
費用対効果を見たいのであれば、今回のデータは直接的な予算金額ベースとは異なりますから、もしOOHの広告費が安いのであれば、費用対効果的にはそれほど悪くないという可能性もありえます。
また、時期も含めて、「いつ、何を投下すべきか」検討したい場合には、積極的にOOHの予算削減まで言及しなくても良いように思います。
分析目的と、モデルの信頼性がポイントになってくるかと思います。
回答
私自身もMac環境なのですが、同様の現象が再現できておりません。もう少し詳しくご教示いただければと思います。
ターミナルにて、
conda install -c conda-forge mlxtend
を実行してもうまくいかないとのことですが、ターミナル上ではどのような反応(表示メッセージなど)なのでしょうか。
上記を実行すると、通常、ターミナル上に下記のようなメッセージが流れたのち、インストール継続確認の “y/n?” を聞かれるのですが、何も表示されない状況なのでしょうか。
Retrieving notices: …working… done
Collecting package metadata (current_repodata.json): done
Solving environment: done
あとは、Jupyter Notebook上で、
!conda install -c conda-forge mlxtend(先頭にビックリマークを付与)
の実行もお試しいただけたらと思います。
上記でもうまくいかなければ、ターミナル上から、pip install mlxtendを実行してみてください。
回答
相関行列の1行目には正しく数値が表示されているとのこと、seabornライブラリ側のバグの可能性があるかと思います。
下記でも同様の現象が報告されていますが、seabornのバージョンアップで解決されています。
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q10296680025
下記の通り、seabornのバージョンアップを試して見ていただけますでしょうか。
(再掲:Anaconda環境→ Jupyter Notebook上で !conda update seaborn / それ以外の環境→ Jupyter Notebook上で !pip install seaborn –upgrade)
※バージョンアップ後、Jupyter Notebookの再起動が必要です
上記で解消されない場合、seabornのバージョン、matplotlibのバージョンをご教示いただければと思います。
▼seabornバージョン確認方法
import seaborn as sns
print(sns.__version__)
▼matplotlibのバージョン確認方法
import matplotlib
matplotlib.__version__
回答
この集計後の「日付」列は、仰せの通り、意味をなさない列です。
非表示化するためには、下記のコードにて、当該日付列をdropしていただければと思います。
df_by_month = df.groupby( df[‘日付’].dt.month ).mean().drop(columns=’日付‘)
また、集計後の「月」の列名が日付のままで違和感ある場合は、下記コードで列名を修正することもできます。
df_by_month = df.groupby( df[‘日付’].dt.month ).mean().drop(columns=’日付’).reset_index().rename(columns={‘日付‘:’月‘})
また、こうなってしまう理由ですが、日付列の「月」で集計を行った際、自分自身の列すなわち「日付」列に対しても(意味なく)月毎の集計を行ってしまっています。
例えば1月の場合、「2015年1月」 「2016年1月」 「2017年1月」 に該当するデータの日付の平均値を無理やり求めており、
その計算結果が 2016年8月5日 16:00:00 になっているものと思われます。月によっては秒数まで端数が出るため、このような細かい数値になっています。
(なお、.mean() 部分を .max() に変えれば、今度は2017年の当該月の月末値が表示されるかと思います)
回答
改めて私の方でも実行してみたのですが、動画と同じ結果になっています。
74行目がTrueとのことですが、当該行の日付は2017/1/9になっていますでしょうか。
![]()
また、お手数ですが、下記コードを実行いただいて、出力された表のキャプチャも、質問アドレス宛にメールお送りいただけたらと思います。
df[df[‘休日フラグ’]==True]
回答
ライブラリのバージョンに依存している可能性もあるので、下記コードにて出力されるバージョンをご教示ください。
import mlxtend
print(mlxtend.__version__)
回答
今回の協調フィルタリング手法も含め、レコメンデーションの多くは基本的に教師なし学習なので、レーティングの値まで精度良く合わせに行くのはなかなか難しい部分もあります。
特に、レーティングの値は蓄積された学習データに大きく依存します。
実際、下記コードで「いか」スコアの頻度集計を見ると、評価4の割合が高くなっており(4: 613件、3: 378件、2:265件、1: 133件、0: 68件)、それに引っ張られているであろうことが推測されます。
df_score[‘3:いか’].value_counts()
そのため、レーティングそのものよりも、相対的な順位(ランク)で捉えた方が良いことも多いです。(レーティングを予測したければ回帰分析の方が適合することもある)
なお、「いか」が2.8で実際の評価4から乖離 していたとのこと、私の環境で実行すると「いか」の評価は「3.066」となったのですが、
もし3.066とすると、このユーザー(ID: 0)の中では最もランキングが高いネタであることになり、(定量的にはあまり合っていなくても)定性的な傾向、相対的な位置付けとしては合致していると思います。
講義では割愛しましたが、レコメンデーションにも評価指標は存在しており、
今回のようなレーティング(数値)予測の場合、通常の数値予測と同じような精度指標(MAE: 平均絶対誤差、RSME: 二乗平均平方根誤差など )を用いて、その予測精度を評価することもありますが、
上述の通り、レーティングまで精度良く合わせに行くのは難しい部分もあることから、あくまで 「ランキング(順位)」 さえ合っていれば良いというスタンスで、ランクの精度指標(MRR: 平均逆順位、nDCG: 減損累積利得 など)を用いることもあります。
回答
“FutureWarning” は、将来のライブラリアップデートで廃止予定の関数を用いている場合に、出力されるWarningです。
したがって、現時点(実行できている今時点)では問題は発生していません。
私の環境では当該Warningが出ないため、下記の共有をお願いします。
・使用pandasのバージョン
・エラー文の全体(いただいた略文だけでは、コードの何行目でエラーが起こっているか不明のため)
(参考:pandasバージョンの確認方法)
import pandas as pd
print(pd.__version__)
バージョンに起因する問題が多いように思うので、WarningやError、また動画と結果が異なる、などの場合は、
先のmlxtendのように、下記コードにて出力されるバージョンをご教示ください。
import ライブラリ名
print(ライブラリ名.__version__)
回答
Webサイトへのリアルタイム実装は十分可能です。
というのも、レコメンデーション分析はそもそも、ユーザーへのアイテム推薦機能としてAmazonやNetflixはじめ、様々なサービスやECサイトで運用されています。
特に、YouTubeやInstagramはサイト自体がPythonベースで作られているようなので、
Pythonで作られたレコメンデーションモデル(実際には講義で扱ったモデルよりももっと複雑と思います)がそのまま組み込まれている可能性もあるかと思います。
アソシエーション分析についても、リアルタイムに頻出パターンのアイテム組合せを提示することは可能ですが、
どちらかというとこちらはシステムに組み込むというよりも、レシートデータを用いて、様々な「意外性のある」同時購入のパターン(例えば、オムツとビール、咳止めとジュース、など)を見出そうとする発見的な分析手法です。
正解データ不要で分析できる(教師なし学習)ため、ひとまずやってみるか、という感じでやることも多いかと思います。
また、私自身の例で恐縮ですが、この手法を他分野適用して、製造業における不良パターンの同時発生分析や、医療における合併症の分析なども行ったことがあります。
ECサイトレビューの特徴語可視化は、例えば大量のアンケートデータにおける自由記述部分を大まかに内容把握したり、直近のニュースやSNSでの話題把握などに活用されています。
SEOキーワード抽出というのも大変興味深い着眼点で、検索用語は本来単語レベルではありますが、
実際には「分析 アソシエーション 用途」などのように、スペース繋ぎで、ある種の文のような形でデータが収集されるかと思うので、本手法を適用する価値は十分あるように思います。
回答
リフト値は1.0以上が望ましいというよりは、式の定義上、1.0以上でないと有効なルールとはいえない(同時購入の方が単独購入よりも購買が促進されるとは言えない)
ということなので、1.0以上は最低条件であり、より値が高いものを見ていく必要があります。
一方、信頼度と支持度は、データの件数に大きく影響を受けます。
例えば、全体のデータ件数=10000件、うち商品A購入=1000件、うちAもBも購入=100件
→ 信頼度100/1000=0.1、支持度=100/10000=0.01ですが、
商品A購入件数も全体のデータ件数もこの10倍になれば、
→ 信頼度100/10000=0.01、支持度=100/100000=0.001に一気に下がります。
つまり、データによって分母が変わるため、絶対的な比較は難しい指標です。
同一のデータ内で、その大小関係を(相対的に)比較していくことに意味があります。