Pythonによるデータ解析入門
回答
少々文字化けしていて分かりませんでしたが、labelsにtipとあるので、データセットはtipsだと思いますので、それで説明します。
まず、labelsは何の設定か分からないという部分についてお伝えします。講義で使っていたデータは下記データです。
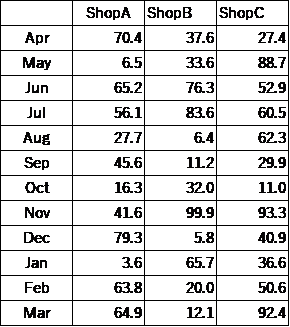
さらに、講義のときの命令文は
#設定
fig, ax = plt.subplots()
NAME = BOX.columns#線の凡例用に、DataFrameの列名を取得
ax.boxplot(BOX,showmeans = True, labels = NAME)
こうなっていたと思います。BOXという変数に上の表のデータが入っています。
ここで、NAMEという変数には、BOXのカラムが格納されていますね?
カラムとは列のことであり、BOX.columnsによって列名が取得されています。
すなわち、labelsには列名を入れているということが分かると思います。
実際のこの命令を実行したら、箱ひげ図が3つ作成されて、ラベルがShopAとBとCになっていたと思います。
ここから、labelsというのはその名の通り、ラベルを振る名前のことです。
さて、tipsのデータで箱ひげ図を作ろうとしてもうまくいかないとことでしたね?
なぜうまくいなかいかというと、tipsのデータは下記の通りです。
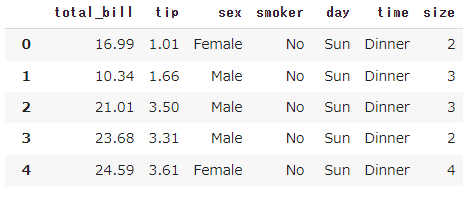
まず
> NAME = I.columns
> ax.boxplot(I,showmeans = True, labels =tip )
ここですが、上図の列名がNAMEに格納されています。
続いて、ax.boxplotによって、Iという変数の箱ひげ図を作れと命令され、平均値も算出しろ、と命令していますが、上図のとおり、どう見ても平均値の算出とか、四分位数の計算すらできなさそうな列が入っていることが分かります。
そのためエラーが出るのです。
四分位計算して箱ひげ図作って、かつ平均値出せと言われたけど、どうやって出したら良いの?とコンピューター側が困っている、という状態です。
なので、たとえば、total_billとtipとsizeの箱ひげ図を出すとしましょう。
まず複数の列を抽出してほかの変数に格納しましょう。
I2 = I[[“total_bill”, “tip”, “size”]]
I2
この時注意するのは、I[“”]で列名を出せたと思いますが、今回複数なので、複数のときにはST = [“a”,”b”,”c”]と[]で入れてましたよね?
だからここでは[]の中に複数の[]を入れていて、[]の中に[]でリスト化していると思います。カッコの数を間違えるとエラーが出るのでお気を付けください。
これで、I2に数値だけのデータフレームができましたので、箱ひげ図を作ってみましょう。
fig, ax = plt.subplots()
NAME = I2.columns
ax.boxplot(I2,showmeans = True, labels =NAME )
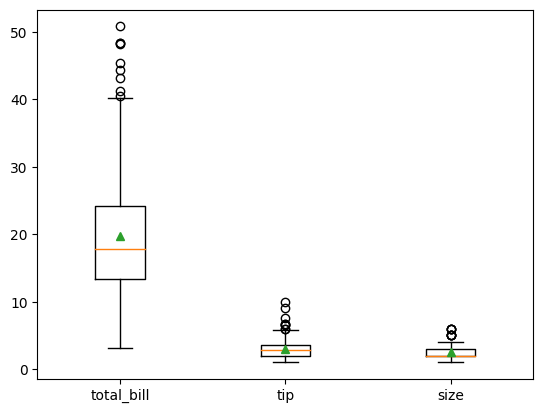
同じ図が出来ましたでしょうか?
もしまた何か分からないことがありましたら、お気軽にお問い合わせください。
回答
I.corr()は、相関係数を算出する関数です。
相関係数を算出するためには、平均値と標準偏差が必要ですね?
すなわち、量的な計算することが可能な状態ではないと計算できません。
恐らくtipsを使っているのだと思うので、そのデータをまず見てみましょう。
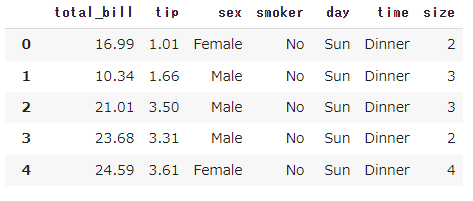
このようなデータがtipsのデータです。
この中から、sexやsmokerなど、平均値と標準偏差が計算できないようなデータが入っています。
Pairplotは動いたとのことですが、図を見ると
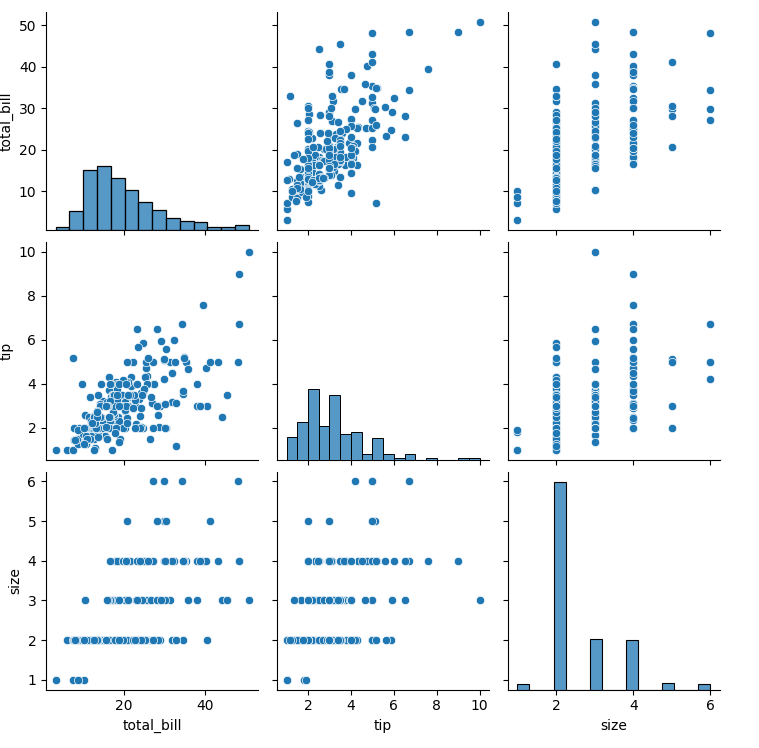
こういう感じでしたよね?
これ、自動的に数値として計算できないものは入ってないことが分かりますか?pairplotは自動的に、数値データじゃないものを除外して、図を作ってくれます。しかしながら、corr()は真面目な関数で、愚直に全てで相関を出そうと頑張ってくれる結果、数値データも計算しようとして、混乱してエラーが出てます。
なので、私たち側がcorr()の関数で計算できるように、数値データだけの変数を作ります。
I2 = I[[“total_bill”, “tip”, “size”]]
I2
このように列を複数選択します。
このとき、注意するのは、I[“”]で列名を出せたと思いますが、今回複数なので、複数のときにはST = [“a”,”b”,”c”]と[]で入れてましたよね?
だからここでは[]の中に複数の[]を入れていて、[]の中に[]でリスト化していると思います。
カッコの数を間違えるとエラーが出るのでお気を付けください。
このI2に対して、corr()をやってみてください。恐らく問題なく動くと思います。
ちなみに、sexやsmokerをダミー変数としてreplaceしてってことであれば、相関係数も算出可能になります。
またはget_dummiesなどを使って、ダミー変数に変換するとそのまま使えたりします。
回答
Python3が表示されない場合で考えられるのはPython3がインストールされていないことが原因である可能性が高いと考えられます。
以下のサイトにあります、ダウンロードのページからPython3をダウンロードし、インストールしてみてください。
https://www.python.org/
これによって表示されるようになると思われます。
回答
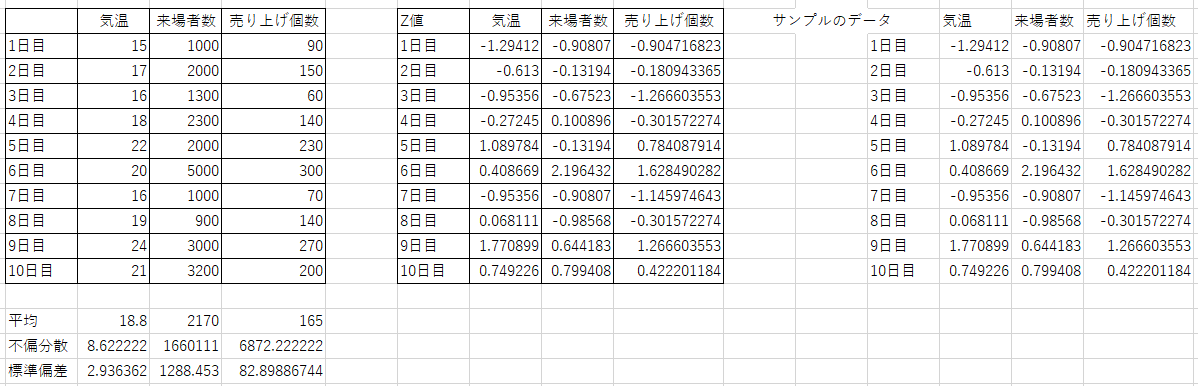
こちらのZ値の算出は、不偏分散から算出されております。母集団を想定した、分析となるため、回帰分析に使用するZ値は基本不偏分散を使用します。
恐らく値が一致しなかったのは、STDEV.Pの関数での計算を実施していたのではないかと思います。
RでZ値変換の関数を使用すると、基本母集団想定のバラつきが算出され、Pythonでは基本は普通のバラつきが算出されます。
回答
3つのパターンを考えてみました。
エラーが発生した場合、エラーコードも合わせてお送りいただけますと、より詳細にご案内できるかと思います。
1.mean() は数値列が対象なので、列に文字列が含まれる場合、DataError: No numeric types to aggregate というエラーになります。
データフレーム変数名.dtypesでデータ型を確認してください。
・たとえば以下のコードは動きますか?
import pandas as pd
# 仮のデータ
data = {
“store”: [“A”, “B”, “A”, “C”, “B”],
“sales”: [100, 200, 150, 300, 250]
}
D = pd.DataFrame(data)
print(D.groupby(“store”).mean().sort_index(ascending=False))
これが動く場合は、上述のとおり、文字列が「store」以外に含まれているからだと思います。
・もし文字列が二つある場合のコード
たとえば、以下のようなデータがあったとします。このとき、「store でグループ化した平均を取りたいが、category は除外したい」とします。
import pandas as pd
data = {
“store”: [“A”, “B”, “A”, “C”, “B”],
“category”: [“x”, “y”, “x”, “z”, “y”],
“sales”: [100, 200, 150, 300, 250]
}
df = pd.DataFrame(data)
df.drop(columns=”category”).groupby(“store”).mean()
上述のように、対象のカラムをdropすることで除外することができます。
2.欠損値が多く含まれているためのエラー
mean() は欠損値(NaN)を自動的に除外しますが、すべて NaN の列では計算できません。
対応策としては、D.isna().sum() で欠損値の有無を確認し、必要に応じて fillna() で埋めるなどの処理をします。
3.グループ化後に数値列が残っていない
たとえば、データフレームに store と product しかない場合、どちらも文字列なら mean() は使えません。
回答
状況の整理しますと、Jupyter Notebook を起動すると、Python 3 ではなく Python [conda env:base] が表示される。Python 3 をインストールし直しても変化なし。ということですね。
であれば、そのまま Python [conda env:base] を使用しても問題ありません。
Python [conda env:base] は、Anaconda のベース環境(base)で動作する Python 3 のカーネルを指しています。つまり、実体としては Python 3 が使われているので、Jupyter Notebook 上では「Python 3」や「base」などと名前が違って見えるだけです。
使用してもよい理由として、Python 3.x がインストールされている、というのがあれば良いですし、Anaconda のベース環境が正しく起動していれば、実行されるコードは Python 3 で解釈されます。
どうしても「Python 3」だけを表示させたい場合は、以下の方法でカーネルの表示名を調整できます。
方法①:IPython kernel を明示的に再インストール
conda activate base
python -m ipykernel install –user –name python3 –display-name “Python 3”
→ これにより「Python 3」という名前のカーネルがJupyter上に表示されるようになります。
あとは新しい仮想環境を作成する方法もありますが、一応上だけで十分かとは思います。