Rによる統計学(実践編)
回答
残差についてですが、例えば以下のデータで実施してみましょう。
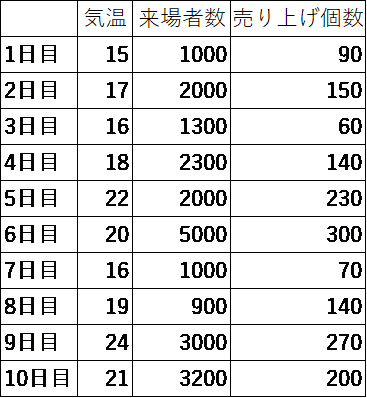
売り上げ個数を従属変数(目的変数)として、残りの気温、来場者数を説明変数として分析すると以下のような結果が出てきました。

結構良さそうな結果です。残差がどうなっているかを出してみて、表の横につけてみます。
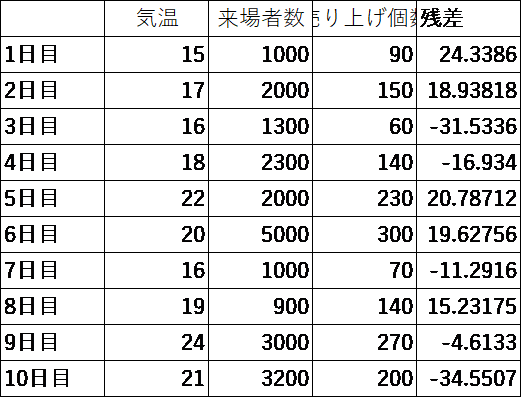
残差でみると、3日目および10日目が大きくマイナスで外れています。マイナスとして出ているということは、今回作ったモデルの式で算出した売上個数よりも、実際には-34個も売れなかったということです。ここで重要な視点は、作成したモデルで計算して算出した売上個数よりも、実際はもっと売れた!ということであれば、だれも怒らないのですが、予測値よりも売れなかった!となると当然怒り出す人もいるでしょう。
ここで3日目および10日目のデータを見ると、来場者数は多いのです。にもかかわらず、売れなかったということは、たとえば、このイベント会場に、何かのライブがあったりして、有名人が来た日が3日目と10日目かもしれません。そういうのを調べて、今度は有名人のライブがあったかどうかをダミー変数として入れてみましょう。以下のような感じです。
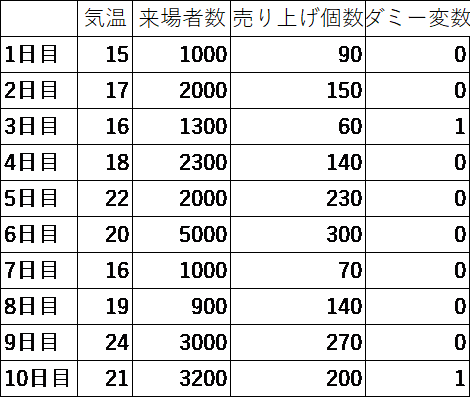
このデータで回帰分析をすると、より一層モデルが良くなりました。

このように、残差を出してあげて、大きく違うところに着目して、何が原因で大きく違うのかを考えて、データを追加したり、もしデータがなければ仮説をたてて、今後はこういうデータも追加でとりましょうと提案したり、色々な手がうてて、より一層モデルが良くなるように働きかける作業が残差を確認していく作業です。
回答
先に回答を伝えると、
1.n数が異なっても、そのままWilcoxon順位和検定を適用できます。
2.検定統計量は「順位和をサンプルサイズに応じて補正」しているので、比較可能です。
3.ただし、片方の群が極端に小さい場合は、検出力の低下に注意してください。
講義では概念的にお伝えしておりますが、n₁ ≠ n₂のケースでも定義されています。式でお伝えすると、
UA=nAnB+nA(nA+1)/2−RA
nAnB:A群・B群のサンプルサイズ
RA:A群の順位和
この式に nA, nB が両方入っているので、サンプルサイズの違いが自然に補正される仕組みになっています。