実践統計学
回答
伸び率はパーセント・データですね。幾何平均にするというのは正しいと思います。また箱ひげ図の基本的な意味も正しくご理解されていると思いますが、パーセント・データを箱ひげ図にするのはあまり好ましくないと思います。
四分位数の計算過程でデータの差を取りますが、分母の異なる比率の場合、単純に差を取ると実体と合わなくなります。
例えば、A組(30人)の文系志望者60% 理系志望者40% という場合。
60%―40%=20% 文系志望者が20%多い。
この結論はOKです。分母が同じなので。
次に、A高(300人)の●大学志望5%、B高(600人)の●大学志望5% という場合。
「A高もB高も5%で差は0だ」と思ったら危険です。実体は、A高には15人、B高には30人志望者がいて、推薦枠が一定ならば、圧倒的にB高の方がライバルが多いのです。
このように、パーセント・データは相対的な変動の情報は保有していますが、絶対的な変動の情報は保持していません。他にもいろいろと問題があり、パーセント・データを統計分析に用いる場合は慎重に行わなければなりません(「「定数和制約」といいます)。
基本的なお悩みは、「外れ値を検出したい」ということでよろしいでしょうか。
外れ値というのは文脈で変わってきます。
その文脈を一番よく理解しているのは分析者です。
例えば、月ごとの売上の推移を示す折れ線グラフを作ってみて、ある店舗のある月だけが飛びぬけて高い。調べてみると、そのとき特別な企画を行っている。それならば飛びぬけて高いことの説明が十分につくので、分析者の判断でその月を幾何平均から除外すれば良いのです。
ただし、分析結果を公表するときは除外した理由をきちんと明示し、恣意的な操作と誤解されないようにしましょう。
回答
まず、効果量の基本的な考え方ですが、母平均の差μ1-μ2を母標準偏差σで割った母効果量δを標本から推定するものです。
![]()
対応のないデータの場合、分子には2つの標本平均の差を用います。分母は、2群の標本分散をその標本サイズで重みづけて平均をとった量を用います。2群に共通な分散に対応する標本統計量として合理的な量になります。
対応のあるデータの場合、対応のないデータと同じ式で計算することもできなくはありません。しかしその場合、2群間に想定される相関関係を全く無視して計算することとなります。それを避けるため、2群の差得点を求め、そこから効果量を計算します。対応のあるデータなど対して2群間の相関を考慮して差得点に基づいた分析を行うことは統計学でしばしば行われます。
回答
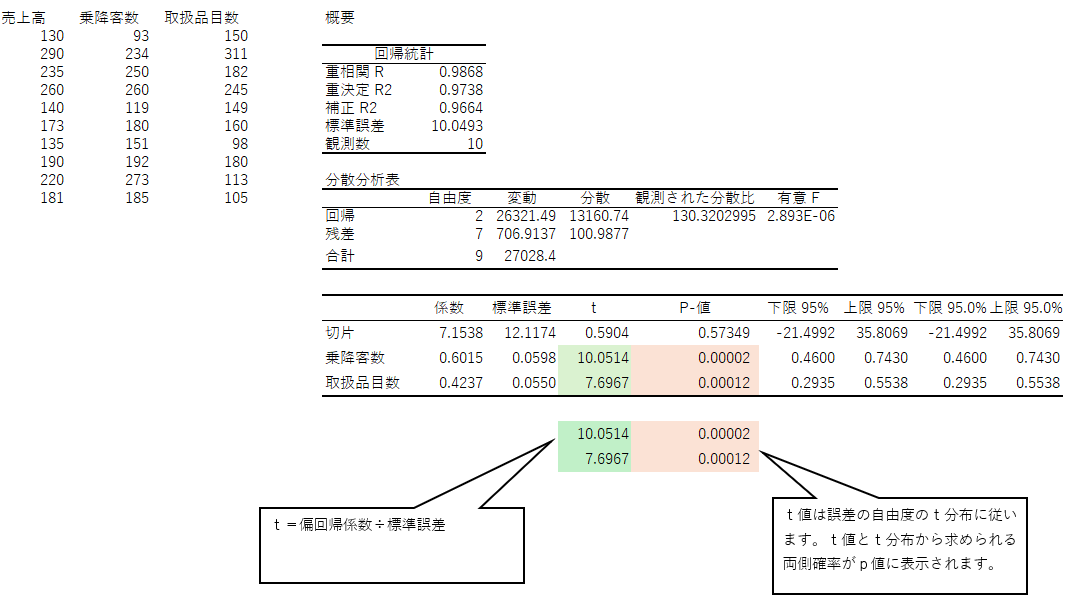
Excelの分析ツールはちょっとお節介なところがあって、切片のp値が0.2069と表示されていますが、これは分析には特に必要のない数字です。ここでのp値は、「母集団において0である」可能性を検討しているものです。切片(定数)は0であっても別に構わないことがほとんどんなので、43.992が有意かどうか、そもそも検討自体しないことが普通です。
一方、偏回帰係数ではp値が大切です。もし母集団において偏回帰係数が0の可能性を棄却できないならば(=有意でないならば)、その説明変数は予測にあまり必要のない変数ということになります。従って、偏回帰係数のp値が有意かどうか確認することが大切です。
回答
有意でない偏回帰係数の数に決まりや目安は特にありません。お書きのとおり、大切なのは決定係数になります。
重回帰式(モデル)に使用する説明変数を探索的に決める方法として「ステップワイズ法」というものがあります。
いったん全ての説明変数を分析に投入した後、段階的に有意でないものを 1 つずつ除去していき、最終的に最も決定係数が大きくなるモデルを採用するやり方です。
ステップワイズ法を EXCEL で行う場合、何回か重回帰分析を繰り返す必要がありますが、統計分析パッケージによっては予めオプションで搭載しているものもあります。よく使われる手法です。
回答
第1四分位数(252)を例に説明します。
基本的に、第1四分位数はデータを大きさ順に並べて、小さい方から見て4分の1(25%点)のところにある値を指します。
データが100個あれば、小さい方から25番めの値が第1四分位数です。
100人のランナーが10キロ走り、着順に1位~100位まで順位をつけたとします。
このとき25位のランナーのタイムが第1四分位数です。
セミナーの例の場合、データは9個しかありませんので、25%点は230(22%)と252(33%)の間にあります。
このような場合、25%点を越えて最初の値、すなわち252を第1四分位数とします。
第3四分位数も同様です。
75%点を越えて最初の値、すなわち331が第3四分位数になります。

回答
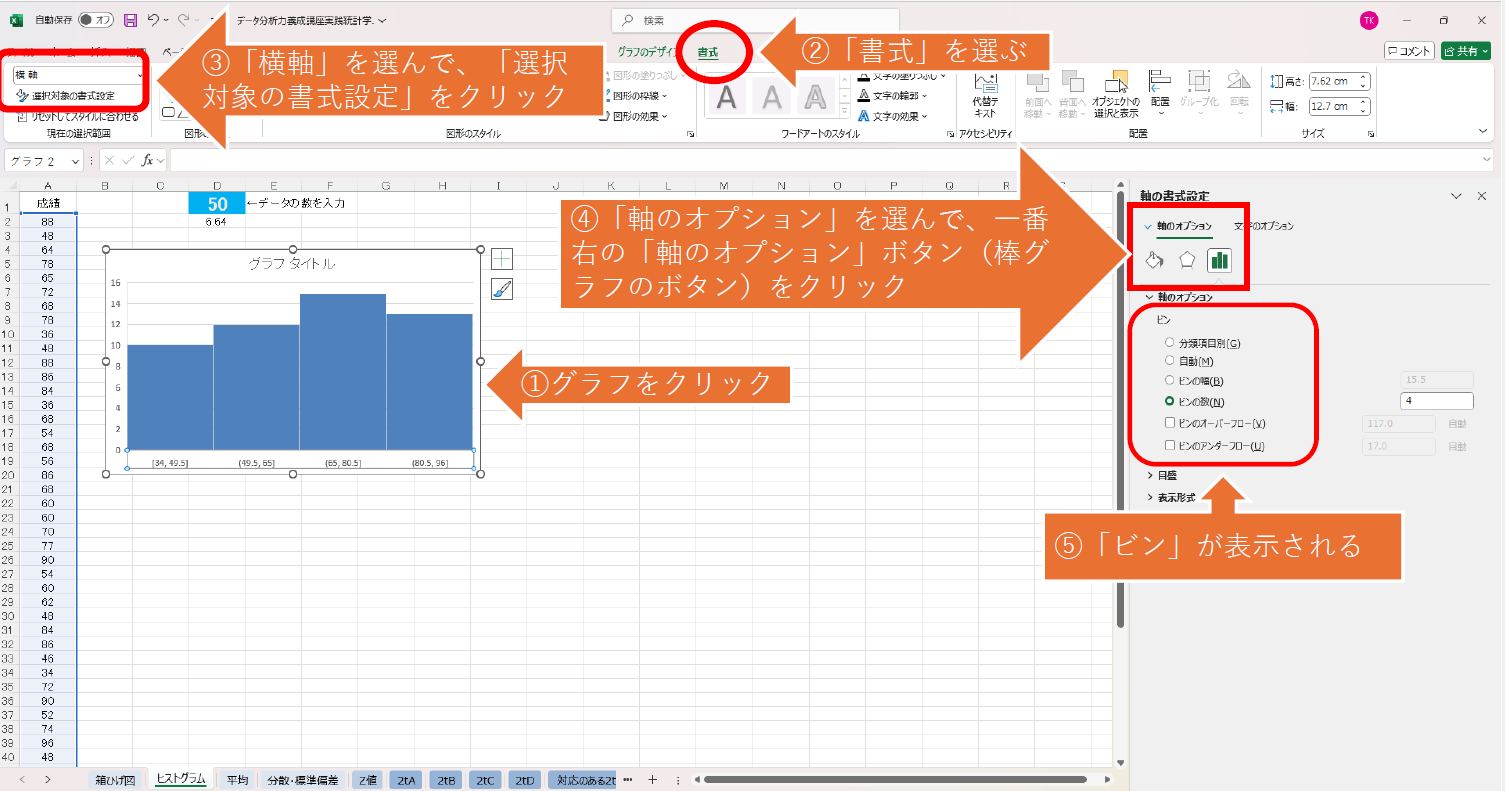
Excelはwindows版をお使いでしょうか?
もし、windowsではなくExcel for macをお使いでしたら、
「横軸」ではなく「データ系列の書式設定」に進んでください。
「ビン」が出てくると思います。
もしwindows版をお使いでしたら、動画のやり方で出来るはずです。
手順を一枚にしたものを添付します。
参考にしてください。
回答
このt検定は、母集団において「偏回帰係数が0である」(帰無仮説といいます)可能性を検討しているものです。
もし有意ならば(p値が5%未満ならば)、帰無仮説は棄却され、母集団において「偏回帰係数は少なくとも0ではない」という結論になります。
とても回りくどいですね。
でも教科書的な説明だと、どうしてもこうなってしまうのです。
もう少し実務的な説明をしますね。
p値が有意だということは、この説明変数は
「予測に全く役立っていないことはない ≒ 予測に役立っている」と考えます。
同じことじゃないかと思われるかもしれませんが、厳密には前者と後者は意味が異なります。
しかし、「p値が有意だから、この説明変数はモデルに入れておこう」とか「p値が有意でないので、この説明変数はモデルから除外しよう」という使われ方が実務ではよくされます。
効果量のところで話しましたが、p値はサンプルサイズが大きいと他が一定でも有意になりやすいという数理的な性質があります。この場合も同じです。サンプルサイズが大きいと、その有意性は説明変数のパワーではない可能性を否定できません。
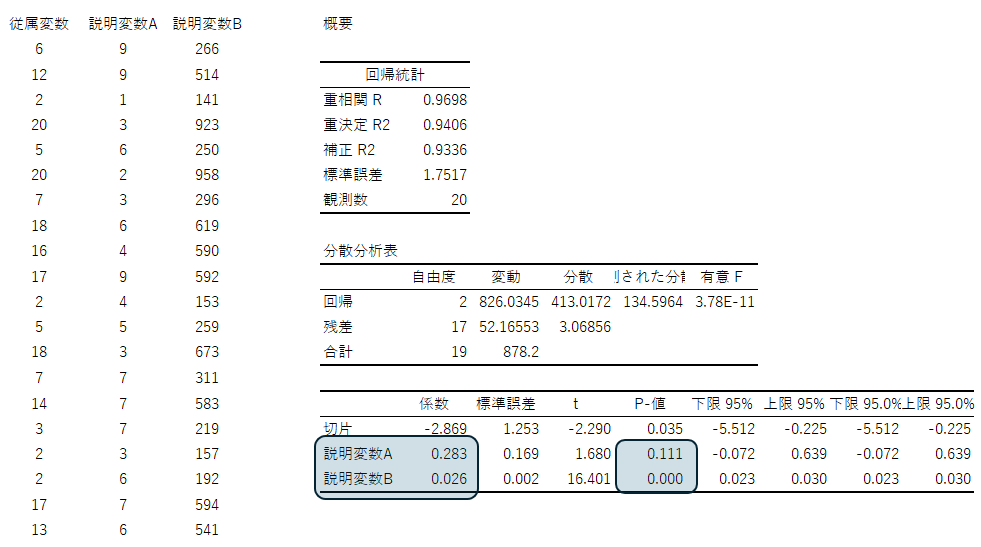
p値と違って、標準偏回帰係数はサンプルサイズの影響をほとんど受けません。
重回帰分析で説明変数同士の影響力の比較をしたい場合は、p値ではなく標準偏回帰係数を用いられた方がよいでしょう。
回答
回答
これはとても難しい質問ですがとても良い質問です。
数字の上では、色々な組み合わせで(試行錯誤しながら)偏相関係数を算出してみて、相関係数と大きく値が異なる場合があれば、その交絡要因が特徴を作っている可能性があると言えるでしょう。
いろんな統計パッケージに偏相関のコマンドが搭載されていますので、少し時間をかければこれは意外と簡単に出来ます(例えばRですとpsychパッケージに「partial.r」という関数があります)。でも結局そこから何を読み取るかは、分析者の専門性(変数に対する知識)に依存します。
また、たまたま手元にある変数で手当たり次第偏相関係数を計算したところで、本当の交絡要因を測定していなければ意味はありません。
実験計画(あるいは調査の計画)を立てる段階で、「これは交絡要因になるかも?」という変数をあらかじめ加えておくべきでしょう。
ここでも、やはり分析者の専門性が肝要となります。