





提出課題5
2024年02月08日 カテゴリー:E.Pythonによるビッグデータ解析
提出課題4
2024年02月08日 カテゴリー:D.Pythonによるデータ解析入門
Pythonによるデータ解析入門
2024年02月08日 カテゴリー:D.Pythonによるデータ解析入門
回答
少々文字化けしていて分かりませんでしたが、labelsにtipとあるので、データセットはtipsだと思いますので、それで説明します。
まず、labelsは何の設定か分からないという部分についてお伝えします。講義で使っていたデータは下記データです。
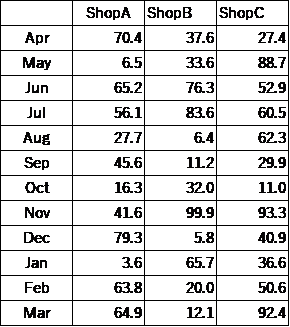
さらに、講義のときの命令文は
#設定
fig, ax = plt.subplots()
NAME = BOX.columns#線の凡例用に、DataFrameの列名を取得
ax.boxplot(BOX,showmeans = True, labels = NAME)
こうなっていたと思います。BOXという変数に上の表のデータが入っています。
ここで、NAMEという変数には、BOXのカラムが格納されていますね?
カラムとは列のことであり、BOX.columnsによって列名が取得されています。
すなわち、labelsには列名を入れているということが分かると思います。
実際のこの命令を実行したら、箱ひげ図が3つ作成されて、ラベルがShopAとBとCになっていたと思います。
ここから、labelsというのはその名の通り、ラベルを振る名前のことです。
さて、tipsのデータで箱ひげ図を作ろうとしてもうまくいかないとことでしたね?
なぜうまくいなかいかというと、tipsのデータは下記の通りです。
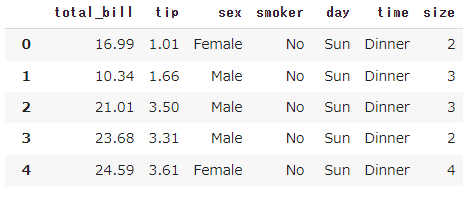
まず
> NAME = I.columns
> ax.boxplot(I,showmeans = True, labels =tip )
ここですが、上図の列名がNAMEに格納されています。
続いて、ax.boxplotによって、Iという変数の箱ひげ図を作れと命令され、平均値も算出しろ、と命令していますが、上図のとおり、どう見ても平均値の算出とか、四分位数の計算すらできなさそうな列が入っていることが分かります。
そのためエラーが出るのです。
四分位計算して箱ひげ図作って、かつ平均値出せと言われたけど、どうやって出したら良いの?とコンピューター側が困っている、という状態です。
なので、たとえば、total_billとtipとsizeの箱ひげ図を出すとしましょう。
まず複数の列を抽出してほかの変数に格納しましょう。
I2 = I[[“total_bill”, “tip”, “size”]]
I2
この時注意するのは、I[“”]で列名を出せたと思いますが、今回複数なので、複数のときにはST = [“a”,”b”,”c”]と[]で入れてましたよね?
だからここでは[]の中に複数の[]を入れていて、[]の中に[]でリスト化していると思います。カッコの数を間違えるとエラーが出るのでお気を付けください。
これで、I2に数値だけのデータフレームができましたので、箱ひげ図を作ってみましょう。
fig, ax = plt.subplots()
NAME = I2.columns
ax.boxplot(I2,showmeans = True, labels =NAME )
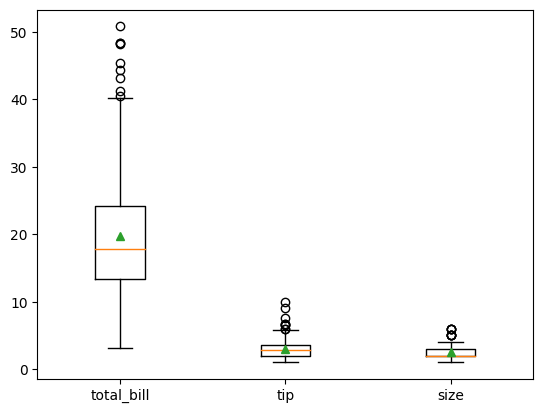
同じ図が出来ましたでしょうか?
もしまた何か分からないことがありましたら、お気軽にお問い合わせください。
回答
I.corr()は、相関係数を算出する関数です。
相関係数を算出するためには、平均値と標準偏差が必要ですね?
すなわち、量的な計算することが可能な状態ではないと計算できません。
恐らくtipsを使っているのだと思うので、そのデータをまず見てみましょう。
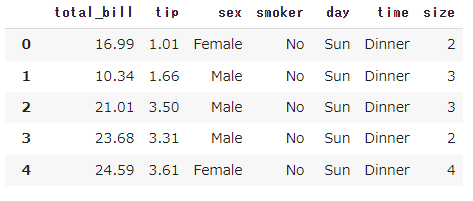
このようなデータがtipsのデータです。
この中から、sexやsmokerなど、平均値と標準偏差が計算できないようなデータが入っています。
Pairplotは動いたとのことですが、図を見ると
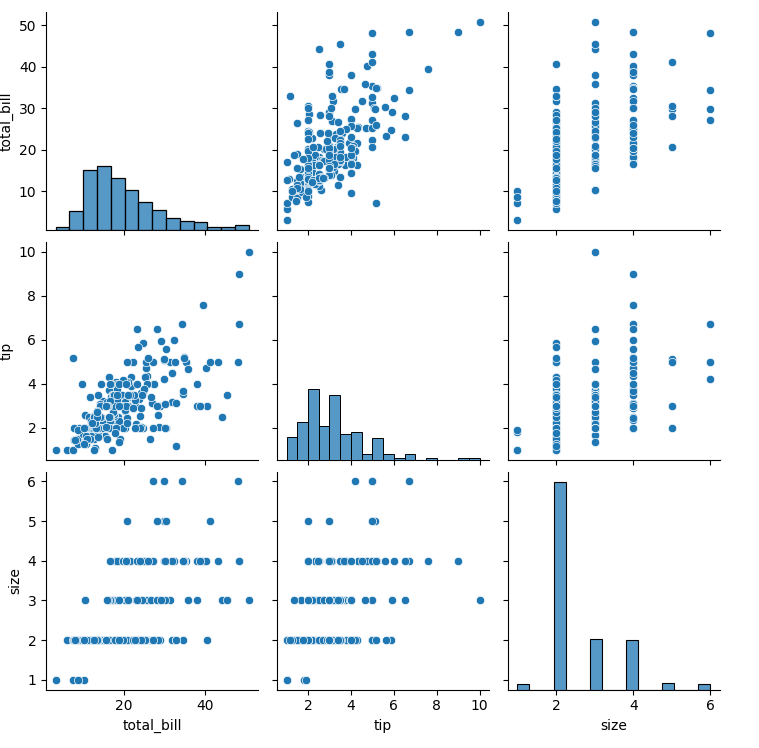
こういう感じでしたよね?
これ、自動的に数値として計算できないものは入ってないことが分かりますか?pairplotは自動的に、数値データじゃないものを除外して、図を作ってくれます。しかしながら、corr()は真面目な関数で、愚直に全てで相関を出そうと頑張ってくれる結果、数値データも計算しようとして、混乱してエラーが出てます。
なので、私たち側がcorr()の関数で計算できるように、数値データだけの変数を作ります。
I2 = I[[“total_bill”, “tip”, “size”]]
I2
このように列を複数選択します。
このとき、注意するのは、I[“”]で列名を出せたと思いますが、今回複数なので、複数のときにはST = [“a”,”b”,”c”]と[]で入れてましたよね?
だからここでは[]の中に複数の[]を入れていて、[]の中に[]でリスト化していると思います。
カッコの数を間違えるとエラーが出るのでお気を付けください。
このI2に対して、corr()をやってみてください。恐らく問題なく動くと思います。
ちなみに、sexやsmokerをダミー変数としてreplaceしてってことであれば、相関係数も算出可能になります。
またはget_dummiesなどを使って、ダミー変数に変換するとそのまま使えたりします。
回答
Python3が表示されない場合で考えられるのはPython3がインストールされていないことが原因である可能性が高いと考えられます。
以下のサイトにあります、ダウンロードのページからPython3をダウンロードし、インストールしてみてください。
https://www.python.org/
これによって表示されるようになると思われます。
回答
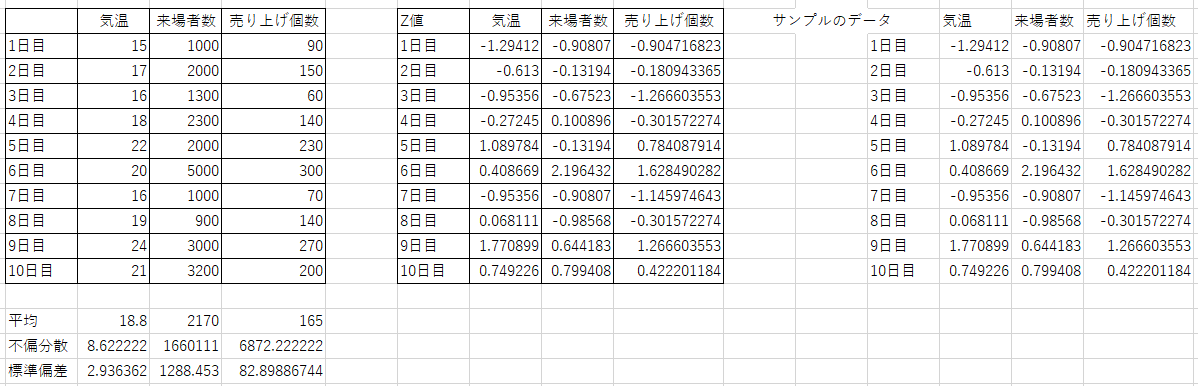
こちらのZ値の算出は、不偏分散から算出されております。母集団を想定した、分析となるため、回帰分析に使用するZ値は基本不偏分散を使用します。
恐らく値が一致しなかったのは、STDEV.Pの関数での計算を実施していたのではないかと思います。
RでZ値変換の関数を使用すると、基本母集団想定のバラつきが算出され、Pythonでは基本は普通のバラつきが算出されます。
Rによる統計学(実践編)
2024年02月08日 カテゴリー:C.Rによる統計学(実践編)
回答
残差についてですが、例えば以下のデータで実施してみましょう。
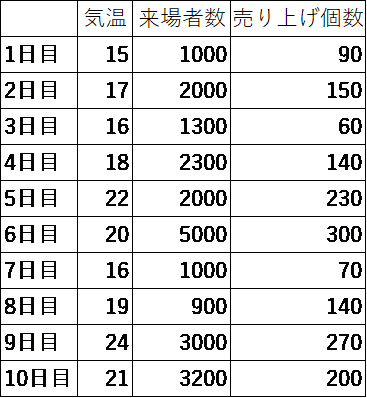
売り上げ個数を従属変数(目的変数)として、残りの気温、来場者数を説明変数として分析すると以下のような結果が出てきました。

結構良さそうな結果です。残差がどうなっているかを出してみて、表の横につけてみます。
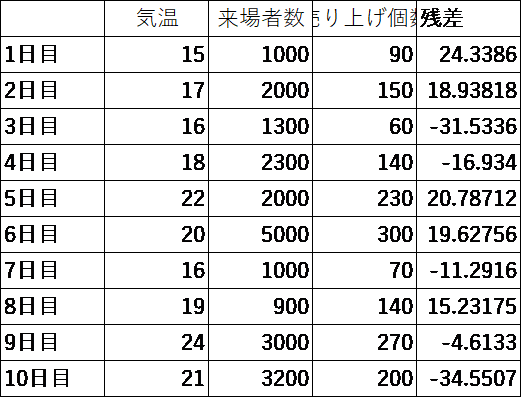
残差でみると、3日目および10日目が大きくマイナスで外れています。マイナスとして出ているということは、今回作ったモデルの式で算出した売上個数よりも、実際には-34個も売れなかったということです。ここで重要な視点は、作成したモデルで計算して算出した売上個数よりも、実際はもっと売れた!ということであれば、だれも怒らないのですが、予測値よりも売れなかった!となると当然怒り出す人もいるでしょう。
ここで3日目および10日目のデータを見ると、来場者数は多いのです。にもかかわらず、売れなかったということは、たとえば、このイベント会場に、何かのライブがあったりして、有名人が来た日が3日目と10日目かもしれません。そういうのを調べて、今度は有名人のライブがあったかどうかをダミー変数として入れてみましょう。以下のような感じです。
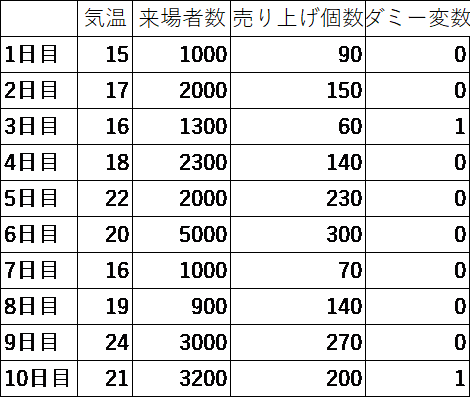
このデータで回帰分析をすると、より一層モデルが良くなりました。

このように、残差を出してあげて、大きく違うところに着目して、何が原因で大きく違うのかを考えて、データを追加したり、もしデータがなければ仮説をたてて、今後はこういうデータも追加でとりましょうと提案したり、色々な手がうてて、より一層モデルが良くなるように働きかける作業が残差を確認していく作業です。
